Nama : Brandon
NIM : 2301903456
Dosen : Wawan Cenggoro, Henry Chong, Ferdinand Ariandy Luwinda
DATA STRUCTURES
Linked List
Linked List atau senarai berantai adalah struktur data yang terdiri dari urutan record data dimana setiap record memiliki field yang menyimpan alamat/referensi dari record selanjutnya. Elemen data yang dihubungkan dengan dengan link pada Linked List disebut Node. Di dalam Linked List, biasanya terdapat Head yang merupakan elemen yang berada pada posisi pertama dalam suatu Linked List dan Tail yang merupakan elemen yang berada pada posisi terakhir dalam suatu Llinked List.
Meski memiliki konsep yang mirip dengan Array, Linked List memiliki keuntungan dalam penyisipan dan pembuangan data dibandingkan Array. Hanya saja, kelemahannya terletak pada cara mengakses data didalamnya. Pada konsep Linked List, pengaksesan data didalamnya harus secara berurutan dari awal, hal ini dikarenakan linked list tidak mengenal indeks seperti Array.
Jika pada Array dikenal istilah index (indeks), maka Linked List mengenal istilah nodes atau titik. Hal ini terjadi karena Linked List menggunakan alokasi memori yang selalu berbeda dan menghubungkannya dengan memory address yang lain, sehingga kita akan lebih mudah memahaminya dengan nodes.
Macam-macam Linked List:
1. Circular Single Linked List
typedef struct TNode{
int data;
TNode *next;
};
2. Doubly Linked List

Doubly Linked List adalah sekumpulan node data yang terurut linear atau sekuensial dengan dua buah pointer yaitu prev dan next. Doubly Linked List memiliki data dan dua buah reference link (biasanya disebut next dan prev) yang menunjuk ke node sebelum dan node sesudahnya. Pada implementasinya, terdapat dua variasi double linked list yaitu circular dan non-circular layaknya pada single linked list. Operasi pada Doubly Linked List:
1. Insert
struct tnode *a = ??;
struct tnode *b = ??;
// the new node will be inserted between a and b
struct tnode *node =
(struct tnode*) malloc(sizeof(struct tnode));
node->value = x;
node->next = b;
node->prev = a;
a->next = node;
b->prev = node;
2. Delete
- If the node to be deleted is the only node:
free(head);
head = NULL;
tail = NULL;
- If the node to be deleted is head:
head = head->next;
free(head->prev);
head->prev = NULL;
- If the node to be deleted is tail:
tail = tail->prev;
free(tail->next);
tail->next = NULL;
- If the node to be deleted is not in head or tail:
struct tnode *curr = head;
while ( curr->next->value != x ) curr = curr->next;
struct tnode *a = curr;
struct tnode *del = curr->next;
struct tnode *b = curr->next->next;
a->next = b;
b->prev = a;
free(del);
Contoh:
struct tnode {
int value;
struct tnode *next;
struct tnode *prev;
};
struct tnode *head = 0;
3. Circular Doubly Linked List

Circular Doubly Linked List mirip dengan Single Linked List, namun jumlah pointer pada setiap node adalah 2. Setiap node pada linked list mempunyai field yang berisi data dan pointer ke node berikutnya & ke node sebelumnya. Untuk pembentukan node baru , mulanya pointer next dan prev akan menunjuk ke nilai NULL. Selanjutnya pointer prev akan menunjuk ke node sebelumnya , dan pointer next akan menunjuk ke node selanjutnya pada list.
Contoh:
#include <stdio.h>
struct TNode{
char data[30];
TNode *next;
TNode *prev;
};
4.Multiple Linked List

Multiple linked list merupakan senarai berantai yang memiliki link atau pointer lebih darisatu. Untuk multiple linked list yang memiliki dua link biasanya disebut sebagai doublylinked list (senarai berantai ganda). Senarai berantai ganda memiliki dua buah pointer yang biasanya masing-masing menunjuk ke simpul sebelumnya dan ke simipul sesudahnya.
Single Linked List
Pendeklarasian struct dari sebuah node single linked list:
struct tnode {
int value;
struct tnode* next;
};
struct tnode* create_node(int value){
struct tnode* node = (struct tnode*)malloc(sizeof(struct tnode));
node->next = NULL;
node->value = value;
return node;
}
Dari single linked list di atas, dapat dilakukan beberapa operasi, yaitu:
1. Push Head
struct tnode* insert_head(struct tnode* head, int value){
struct tnode* new_node = create_node(value);
new_node->next = head;
head = new_node;
return head;
}
function di atas berfungsi untuk menginsert node baru sebagai head atau node awal.
2.Push Tail
struct tnode* insert_tail(struct tnode* head, int value){
if(head==NULL){
head = insert_head(head, value);
} else {
struct tnode* new_node = create_node(value);
struct tnode* temp = head;
while(temp->next!=NULL){
temp = temp->next;
}
temp->next = new_node;
}
return head;
}
function di atas berfungsi untuk menginsert node baru sebagai tail atau node akhir.
3.Pop Head
struct tnode* delete_head(struct tnode* head){
struct tnode* temp = head;
head = head->next;
free(temp);
return head;
}
function di atas berfungsi untuk mendelete node head.
4.Pop Tail
struct tnode* delete_tail(struct tnode* head){
struct tnode* temp = head;
struct tnode* temp2 = head->next;
if(temp2==NULL){
head = NULL;
free(temp);
} else {
while(temp2->next!=NULL){
temp = temp->next;
temp2 = temp2->next;
}
temp->next = NULL;
free(temp2);
}
return head;
}
function di atas berfungsi untuk mendelete note tail.
Hashing Table & Binary Tree
Hashing
Hashing adalah teknik yang digunakan untuk menyimpan dan mengambil kunci dengan cepat. Hashing digunakan untuk mengindeks dan mengambil item dalam database karena lebih cepat menemukan item menggunakan kunci hash yang lebih pendek daripada menemukannya menggunakan nilai asli.
Hashing juga dapat didefinisikan sebagai konsep mendistribusikan kunci dalam array yang disebut hash table menggunakan fungsi yang telah ditentukan yang disebut hash function.
Hash Table
 Tabel hash adalah tabel tempat menyimpan string asli. Indeks tabel adalah kunci hash dan nilainya adalah string asli. Ukuran tabel hash biasanya berupa urutan yang besarnya lebih rendah dari jumlah total string yang mungkin, sehingga beberapa string mungkin memiliki kunci hash yang sama.
Tabel hash adalah tabel tempat menyimpan string asli. Indeks tabel adalah kunci hash dan nilainya adalah string asli. Ukuran tabel hash biasanya berupa urutan yang besarnya lebih rendah dari jumlah total string yang mungkin, sehingga beberapa string mungkin memiliki kunci hash yang sama.
Hash Function
Ada beberapa cara untuk membuat fungsi hash.
1. Mid-Square
a. Kuadratkan string / identifier dan kemudian gunakan jumlah bit yang sesuai dari tengah kotak untuk mendapatkan hash-key.
b. Jika kuncinya adalah string, maka akan dikonversi ke angka.
2.Division
a. Membagi string / pengidentifikasi dengan menggunakan operator modulus.
b. Divison merupakan metode hashing integer yang paling sederhana.
3.Folding
Cara melakukan folding yaitu, buat string / identifier menjadi beberapa bagian, lalu tambahkan bagian bersama-sama untuk mendapatkan kunci hash.
4.Digit Extraction
Pada metode ini, Digit yang ditentukan sebelumnya dari nomor yang diberikan dianggap sebagai alamat hash.
5.Rotating Hash
a. Gunakan metode hash mid-square.
b. Setelah mendapatkan kode / alamat hash dari metode hash, lakukan rotasi.
c. Rotasi dilakukan dengan menggeser digit untuk mendapatkan alamat hash baru.
Tree
Tree merupakan struktur data non-linear yang mewakili hubungan hierarkis(one to many) di antara objek data. Tree bisa didefinisikan sebagai kumpulan simpul/node dengan satu elemen khusus yang disebut Root dan node lainnya. Tree juga adalah suatu graph yang acyclic, simple, connected yang tidak mengandung loop. Contoh:

- Node di atas disebut sebagai root.
- Garis yang menghubungkan induk ke anak adalah edge.
- Node yang tidak memiliki anak disebut leaf.
- Node yang memiliki orang tua yang sama disebut sibling.
- Degree dari simpul adalah total sub tree dari simpul.
- Height/Depth adalah tingkat maksimum node dalam tree.
- Jika ada garis yang menghubungkan p ke q, maka p disebut ancestor dari q, dan q adalah descendant dari p.
Binary Tree
Binary tree adalah struktur data rooted tree di mana setiap node memiliki paling banyak dua anak.
Macam-macam binary tree:

- Perfect binary tree adalah pohon biner di mana setiap level berada pada depth yang sama.
- Complete adalah pohon biner di mana setiap level kecuali yang terakhir terisi penuh dan semua node diletakkan sejauh mungkin. Perfect binary tree juga merupakan Complete binary tree.
- Skewed binary tree adalah pohon biner di mana setiap node memiliki paling banyak satu anak.
- Balanced binary tree adalah pohon biner dimana tidak ada leaf yang lebih jauh dari root daripada leaf lainnya.
Konsep binary tree
- Jumlah maksimum node pada level k dari pohon biner adalah 2k.
- Jumlah maksimum node pada pohon biner dengan tinggi h adalah 2^h+1 - 1.
- Ketinggian pohon adalah jumlah level atau level tertinggi h.
- Tinggi minimum pohon biner dari n node adalah 2log (n).
- Tinggi maksimum pohon biner dari n node adalah n - 1.
Expression Tree

Prefix : *+ab/-cde
Postfix : ab+cd-e/*
Infix : (a+b)*((c-d)/e)
Expression tree dapat dibuat dari prefix dengan rekursif.
Struktur Tree yang digunakan:
struct tnode {
char chr;
struct tnode *left;
struct tnode *right;
};
};
main function
struct tnode *root = newnode(s[0]);
f(root);
char s[MAX];
int p = 0;
void f(struct tnode *curr) {
if ( is_operator(s[p]) ) {
p++; curr->left = newnode(s[p]);
f(curr-->left);
p++; curr->right = newnode(s[p]);
f(curr-->right);}}
Prefix Traversal
void prefix(struct tnode *curr) {
printf( “%c “, curr->chr );
if ( curr->left != 0 ) prefix(curr->left);
if ( curr->right != 0 ) prefix(curr->right);}
Postfix Traversal
void postfix(struct tnode *curr) {
if ( curr->left != 0 ) postfix(curr->left);
if ( curr->right != 0 ) postfix(curr->right);
printf( “%c“, curr->chr ); }
Infix Traversal
void infix(tnode *curr) {
if ( is_operator(curr->chr) ) putchar( '(' );
if ( curr->left != 0 ) infix(curr->left);
printf( "%c", curr->chr );
if ( curr->right != 0 ) infix(curr->right);
if ( is_operator(curr->chr) ) putchar( ')' );}
Threaded Binary Tree


Threaded Binary Tree hampir sama dengan pohon biner, namun berbeda dalam menyimpan pointer NULL. Jika thread muncul di bidang kiri disebut left threaded binary tree. Sebaliknya, jika thread muncul di bidang kanan disebut right threaded binary tree. Selain itu, ada juga two way threaded binary tree dimana setiap node di-threaded ke arah pendahulu dan penggantinya secara berurutan (kiri dan kanan) berarti semua pointer nol kanan akan mengarah ke penerus inorder DAN semua pointer nol kiri akan menunjuk ke inorder pendahulu.
Kelebihan Threaded Binary Tree
- memungkinkan lintasan linier elemen pada pohon.
- menghilangkan penggunaan tumpukan yang menghabiskan banyak ruang memori dan waktu komputer.
- memungkinkan untuk menemukan induk dari elemen yang diberikan tanpa menggunakan pointer orangtua secara eksplisit.
Linked List

Macam-macam Linked List:
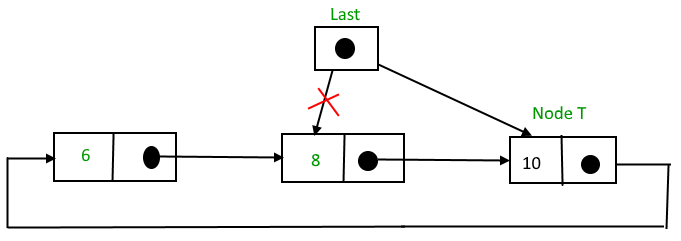
1. Circular Single Linked List
Single Linked List Circular adalah Single Linked List yang pointer nextnya menunjuk pada dirinya sendiri. Jika Single Linked List tersebut terdiri dari beberapa node, maka pointer next pada node terakhir akan menunjuk ke node terdepannya. Circular artinya pointer nextnya akan menunjuk pada dirinya sendiri sehingga berbentuk seperti berputar.
2. Doubly Linked List
Doubly Linked List adalah sekumpulan node data yang terurut linear atau sekuensial dengan dua buah pointer yaitu prev dan next. Doubly Linked List memiliki data dan dua buah reference link (biasanya disebut next dan prev) yang menunjuk ke node sebelum dan node sesudahnya. Pada implementasinya, terdapat dua variasi double linked list yaitu circular dan non-circular layaknya pada single linked list.
3. Circular Doubly Linked List
Circular Doubly Linked List mirip dengan Single Linked List, namun jumlah pointer pada setiap node adalah 2. Setiap node pada linked list mempunyai field yang berisi data dan pointer ke node berikutnya & ke node sebelumnya. Untuk pembentukan node baru , mulanya pointer next dan prev akan menunjuk ke nilai NULL. Selanjutnya pointer prev akan menunjuk ke node sebelumnya , dan pointer next akan menunjuk ke node selanjutnya pada list.
4. Multiple Linked List
Multiple linked list merupakan senarai berantai yang memiliki link atau pointer lebih darisatu. Untuk multiple linked list yang memiliki dua link biasanya disebut sebagai doublylinked list (senarai berantai ganda). Senarai berantai ganda memiliki dua buah pointer yang biasanya masing-masing menunjuk ke simpul sebelumnya dan ke simipul sesudahnya.
Operasi dalam Linked List:
1. Push
Push merupakan operasi untuk memasukkan data pada linked list atau insert. Memasukkan data dapat dari depan(PushDepan) atau dari belakang(PushBelakang) atau juga bisa pada data yang diinginkan.
2. Pop
Pop merupakan operasi untuk menghapus data pada linked list atau delete. Menghapus data dapat dilakukan dari depan(PopDepan) atau dari belakang(PopBelakang) atau juga bisa pada data yang diinginkan.
Hashing & Binary Tree
Hashing adalah teknik yang digunakan untuk menyimpan dan mengambil kunci dengan cepat. Hashing digunakan untuk mengindeks dan mengambil item dalam database karena lebih cepat menemukan item menggunakan kunci hash yang lebih pendek daripada menemukannya menggunakan nilai asli.
Hash Table

Tabel hash adalah tabel tempat menyimpan string asli. Indeks tabel adalah kunci hash dan nilainya adalah string asli. Ukuran tabel hash biasanya berupa urutan yang besarnya lebih rendah dari jumlah total string yang mungkin
Hash Function
Ada beberapa cara untuk membuat fungsi hash.
1. Mid-Square
a. Kuadratkan string / identifier dan kemudian gunakan jumlah bit yang sesuai dari tengah kotak untuk mendapatkan hash-key.
b. Jika kuncinya adalah string, maka akan dikonversi ke angka.
2.Division
a. Membagi string / pengidentifikasi dengan menggunakan operator modulus.
b. Divison merupakan metode hashing integer yang paling sederhana.
3.Folding
Cara melakukan folding yaitu, buat string / identifier menjadi beberapa bagian, lalu tambahkan bagian bersama-sama untuk mendapatkan kunci hash.
4.Digit Extraction
Pada metode ini, Digit yang ditentukan sebelumnya dari nomor yang diberikan dianggap sebagai alamat hash.
5.Rotating Hash
a. Gunakan metode hash mid-square.
b. Setelah mendapatkan kode / alamat hash dari metode hash, lakukan rotasi.
c. Rotasi dilakukan dengan menggeser digit untuk mendapatkan alamat hash baru.
Tree

Binary Tree
Binary tree adalah struktur data rooted tree di mana setiap node memiliki paling banyak dua anak.
Terdapat 4 macam binary tree antara lain : Perfect binary tree, Complete Binary Tree, Skewed binary tree, Balanced binary tree.
Expression Tree
Pohon ekspresi adalah pohon biner di mana setiap node internal sesuai dengan operator dan setiap node leaf sesuai dengan operand.

Prefix : *+ab/-cde
Postfix : ab+cd-e/*
Infix : (a+b)*((c-d)/e)
Linked List
Macam-macam Linked List:
1. Circular Single Linked List
Single Linked List Circular adalah Single Linked List yang pointer nextnya menunjuk pada dirinya sendiri. Jika Single Linked List tersebut terdiri dari beberapa node, maka pointer next pada node terakhir akan menunjuk ke node terdepannya. Circular artinya pointer nextnya akan menunjuk pada dirinya sendiri sehingga berbentuk seperti berputar.
2. Doubly Linked List
Doubly Linked List adalah sekumpulan node data yang terurut linear atau sekuensial dengan dua buah pointer yaitu prev dan next. Doubly Linked List memiliki data dan dua buah reference link (biasanya disebut next dan prev) yang menunjuk ke node sebelum dan node sesudahnya. Pada implementasinya, terdapat dua variasi double linked list yaitu circular dan non-circular layaknya pada single linked list.
3. Circular Doubly Linked List
Circular Doubly Linked List mirip dengan Single Linked List, namun jumlah pointer pada setiap node adalah 2. Setiap node pada linked list mempunyai field yang berisi data dan pointer ke node berikutnya & ke node sebelumnya. Untuk pembentukan node baru , mulanya pointer next dan prev akan menunjuk ke nilai NULL. Selanjutnya pointer prev akan menunjuk ke node sebelumnya , dan pointer next akan menunjuk ke node selanjutnya pada list.
4. Multiple Linked List
Multiple linked list merupakan senarai berantai yang memiliki link atau pointer lebih darisatu. Untuk multiple linked list yang memiliki dua link biasanya disebut sebagai doublylinked list (senarai berantai ganda). Senarai berantai ganda memiliki dua buah pointer yang biasanya masing-masing menunjuk ke simpul sebelumnya dan ke simipul sesudahnya.
Operasi dalam Linked List:
1. Push
Push merupakan operasi untuk memasukkan data pada linked list atau insert. Memasukkan data dapat dari depan(PushDepan) atau dari belakang(PushBelakang) atau juga bisa pada data yang diinginkan.
2. Pop
Pop merupakan operasi untuk menghapus data pada linked list atau delete. Menghapus data dapat dilakukan dari depan(PopDepan) atau dari belakang(PopBelakang) atau juga bisa pada data yang diinginkan.
Hashing & Binary Tree
Hashing adalah teknik yang digunakan untuk menyimpan dan mengambil kunci dengan cepat. Hashing digunakan untuk mengindeks dan mengambil item dalam database karena lebih cepat menemukan item menggunakan kunci hash yang lebih pendek daripada menemukannya menggunakan nilai asli.
Hash Table
Tabel hash adalah tabel tempat menyimpan string asli. Indeks tabel adalah kunci hash dan nilainya adalah string asli. Ukuran tabel hash biasanya berupa urutan yang besarnya lebih rendah dari jumlah total string yang mungkin
Hash Function
Ada beberapa cara untuk membuat fungsi hash.
1. Mid-Square
a. Kuadratkan string / identifier dan kemudian gunakan jumlah bit yang sesuai dari tengah kotak untuk mendapatkan hash-key.
b. Jika kuncinya adalah string, maka akan dikonversi ke angka.
2.Division
a. Membagi string / pengidentifikasi dengan menggunakan operator modulus.
b. Divison merupakan metode hashing integer yang paling sederhana.
3.Folding
Cara melakukan folding yaitu, buat string / identifier menjadi beberapa bagian, lalu tambahkan bagian bersama-sama untuk mendapatkan kunci hash.
4.Digit Extraction
Pada metode ini, Digit yang ditentukan sebelumnya dari nomor yang diberikan dianggap sebagai alamat hash.
5.Rotating Hash
a. Gunakan metode hash mid-square.
b. Setelah mendapatkan kode / alamat hash dari metode hash, lakukan rotasi.
c. Rotasi dilakukan dengan menggeser digit untuk mendapatkan alamat hash baru.
Tree
Binary Tree
Binary tree adalah struktur data rooted tree di mana setiap node memiliki paling banyak dua anak.
Terdapat 4 macam binary tree antara lain : Perfect binary tree, Complete Binary Tree, Skewed binary tree, Balanced binary tree.
Expression Tree
Pohon ekspresi adalah pohon biner di mana setiap node internal sesuai dengan operator dan setiap node leaf sesuai dengan operand.
Prefix : *+ab/-cde
Postfix : ab+cd-e/*
Infix : (a+b)*((c-d)/e)
AVL Tree

AVL Tree dinamai setelah penemunya Adelson, Velski & Landis. AVL Tree adalah Binary Search Tree yang balance. Pohon AVL memeriksa ketinggian sub-pohon kiri dan kanan dan memastikan bahwa perbedaannya tidak lebih dari 1. Perbedaan ini disebut balance factor.
BalanceFactor = height(left-sutree) − height(right-sutree).
Jika balance factor bernilai kurang dari -1 atau lebih dari 1, maka pohon tidak balance dan diperlukan rotasi.
4 Macam Rotasi:
1. Left Rotation
Jika sebuah node menjadi tidak seimbang karena node dimasukkan di subtree kanan, maka dilakukan rotasi kiri.
2. Right Rotation
Jika sebuah node menjadi tidak seimbang karena node dimasukkan di subtree kiri, maka dilakukan rotasi kanan.
3. Left-Right Rotation
Rotasi kiri-kanan adalah kombinasi dari rotasi kiri diikuti oleh rotasi kanan.
4. Right-Left Rotation
Rotasi kanan-kiri adalah kombinasi dari rotasi kanan diikuti oleh rotasi kiri.
Operasi dalam AVL Tree:
1.Search
In an AVL tree, the search operation is performed with O(log n) time complexity. The search operation in the AVL tree is similar to the search operation in a Binary search tree.
2.Insertion
In an AVL tree, the insertion operation is performed with O(log n) time complexity. In AVL Tree, a new node is always inserted as a leaf node.
3.Deletion
The deletion operation in AVL Tree is similar to deletion operation in BST. But after every deletion operation, we need to check with the Balance Factor condition. If the tree is balanced after deletion go for next operation otherwise perform suitable rotation to make the tree Balanced.
B-Tree
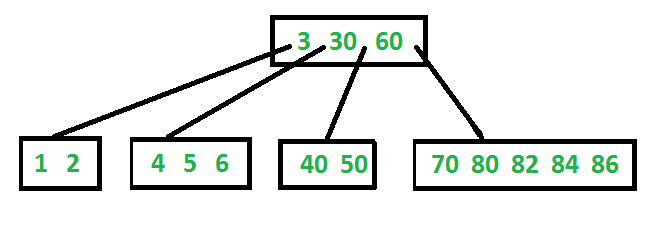
B-Tree adalah self-balancing search tree. Gagasan utama menggunakan B-Tree adalah untuk mengurangi jumlah akses disk. Sebagian besar operasi pohon (pencarian, masukkan, hapus, maks, min, ..etc) memerlukan O (h) akses disk di mana h adalah ketinggian pohon. B-tree adalah pohon yang gemuk. Ketinggian B-Trees dijaga tetap rendah dengan meletakkan kunci maksimum yang mungkin dalam simpul B-Tree. Karena h rendah untuk B-Tree, akses disk total untuk sebagian besar operasi berkurang secara signifikan dibandingkan dengan Binary Search Tree yang lain seperti AVL, Tree, Red-Black Tree.
Ciri-ciri B-Tree
1) Semua leaf berada pada level yang sama.
2) B-Tree didefinisikan dengan istilah tingkat minimum ‘t ’. Nilai t tergantung pada ukuran blok disk.
3) Setiap node kecuali root harus mengandung setidaknya kunci t-1. Root mungkin berisi kunci minimal 1.
4) Semua node (termasuk root) dapat berisi maksimal 2t - 1 kunci.
5) Jumlah anak-anak dari sebuah simpul sama dengan jumlah kunci di dalamnya ditambah 1.
6) Semua kunci simpul diurutkan dalam urutan yang meningkat. Anak antara dua tombol k1 dan k2 berisi semua kunci dalam kisaran dari k1 dan k2.
7) B-Tree tumbuh dan menyusut dari akar yang tidak seperti Binary Search Tree. Binary Search Trees tumbuh ke bawah dan juga menyusut dari bawah.
8) Seperti Pohon Penelusuran Biner seimbang lainnya, kompleksitas waktu untuk mencari, menyisipkan, dan menghapus adalah O (Logn).
Operasi dalam B-Tree
1. Search
Mulai dari root dan secara rekursif melakukan traverse. Untuk setiap node non-leaf yang dikunjungi, jika simpul tersebut memiliki kunci, maka akan mereturn node tersebut. Jika tidak, kembali ke anak yang sesuai (Anak yang tepat sebelum kunci pertama yang lebih besar) dari node. Jika kami mencapai simpul daun dan tidak menemukan k di simpul daun, maka akan mengembalikan NULL.
2. Insert
Key yang diinsert akan selalu masuk ke node leaf. Namun, sebelum menginsert harus dipastikan bahwa ada tempat kosong di node leaf tersebut.
3. Delete
Untuk mendelete sebuah node pada B-Tree harus memperhatikan properties B-Tree.
Heap

Heap adalah tree khusus berbentuk complete binary tree. Ada 2 macam binary tree, yaitu:
1. Max-Heap: Dalam Max-Heap key yang ada di simpul akar harus paling besar di antara key yang ada di semua anak-anak. Properti yang sama harus benar secara rekursif untuk semua sub-pohon di Pohon Biner itu.
2. Min-Heap: Dalam Min-Heap key yang ada di simpul akar harus minimum di antara key yang ada di semua anak-anak itu. Properti yang sama harus benar secara rekursif untuk semua sub-pohon di Pohon Biner itu.
Cara Insert dalam Heap max/min:
1. Buat simpul baru di akhir heap.
2. Tetapkan nilai baru ke node.
3. Bandingkan nilai simpul anak ini dengan induknya.
4. Jika nilai orang tua kurang/lebih dari anak, maka tukarlah.
5. Ulangi langkah 3 & 4 sampai properti Heap bertahan.
Cara Delete dalam Heap max/min:
1. Hapus simpul root.
2. Pindahkan elemen terakhir dari level terakhir ke root.
3. Bandingkan nilai simpul anak ini dengan induknya.
4. Jika nilai orang tua kurang/lebih dari anak, maka tukarlah.
5. Ulangi langkah 3 & 4 sampai properti Heap bertahan.
Aplikasi Heap:
1.Priority Queue
-Selection Algorithms
-Dijkstra’s Algorithm
-Prim Algorithm
2.Heap Sort
Trie

Trie adalah tree yang nodenya menyimpan kata atau string dan disusun di dalam node-node dengan cara tertentu. Sebuah node dalam trie berisi 2 hal, yaitu: value atau NULL dan array referensi ke node anak atau NULL. Waktu untuk mencari, menyisipkan, dan menghapus dari suatu trie tergantung pada panjang kata yang dicari, dimasukkan, atau dihapus, dan jumlah total kata, n, membuat runtime dari operasi ini adalah O(n). Keuntungan dari trie ini adalah dapat dengan mudah mencetak semua kata dalam urutan abjad dan lebih cepat dari BST maupun hashing. Selain itu, dapat melakukan pencarian awalan kata seperti di search engine.
Aplikasi trie:
1.Search Engines
2.Genome Analysis
3.Data Analytics
Binary Search Tree

BST adalah binary tree dimana node kirinya selalu lebih kecil dari node kanannya. Operasi-operasi dalam BST, yaitu search, insert, delete, pre-order traversal, post-order traversal, in-order traversal.
struct node { int data; struct node *leftChild; struct node *rightChild; };
1. Search, search dimulai dari root, jika key yang dicari lebih kecil dari data, maka akan turun ke subtree kiri, jika key yang dicari lebih besar dari tada, maka akan turun ke subtree kanan.
2. Insert, untuk menginsert data, maka harus dimulai dari root, jika key yang akan diinsert lebih kecil dari data, maka akan dicari tempat kosong di subtree kiri, sedangkan jika key yang akan diinsert lebih besar dari data, maka akan dicari tempat kosong di subtree kanan.
3. Delete, node pada bst saling berhubungan, sehingga ada beberapa kondisi yang perlu diperhatikan ketika akan mendelete node, yaitu:
-Jika yang didelete adalah leaf node, maka hanya perlu delete leaf node tersebut.
-Jika yang didelete memiliki 1 child, jika simpul yang akan dihapus adalah anak kiri dari induk, maka dihubungkan pointer kiri induk (dari simpul yang dihapus) ke satu anak. Jika simpul yang akan dihapus adalah anak kanan dari induk, maka dihubungkan pointer kanan induk (dari simpul yang dihapus) ke satu anak.
-Jika yang didelete memiliki 2 child, maka data yang akan diinsert harus dibandingkan dengan data-data pada BST dan mencari pengganti untuk node yang dihapus dari node lain.
Kompleksitas Waktu: Kompleksitas waktu kasus terburuk dari operasi pencarian dan penyisipan adalah O (h) di mana h adalah ketinggian Pohon Pencarian Biner. Dalam kasus terburuk, kita mungkin harus melakukan perjalanan dari root ke simpul daun terdalam.
Red Black Tree

Red Black Tree adalah pohon pencarian biner seimbang yang ditemukan pada tahun 1972 oleh Rudolf Bayer yang menyebutnya "pohon-biner simetris B-tree". Running time untuk operasinya untuk digunakan sebagai pencarian, penyisipan, dan penghapusan semua dapat dilakukan dalam waktu O (log n), di mana n adalah jumlah node di pohon.
RBT Properties:
1. Setiap node berwarna hitam atau merah.
2. Warna root adalah hitam.
3. Semua node eksternal berwarna hitam.
4. Jika simpul berwarna merah, maka kedua anaknya berwarna hitam.
5. Setiap jalur dari leaf ke root memiliki jumlah node hitam yang sama.
RBT Operations: Insertion
Node yang baru diinsert bewarna merah. Namun, perlu diperhatikan:
-Jika induknya berwarna hitam, maka tidak ada pelanggaran yang terjadi.
-Jika induknya merah, maka pelanggaran terjadi.
Fixing the violation
-Misalkan simpul baru adalah q, induknya adalah p, dan siblingnya adalah s (uncle dari q). Jika -parent tidak memiliki sibling, maka s berwarna hitam (simpul eksternal berwarna hitam).
-Jika s berwarna merah, maka ubah p dan s menjadi hitam dan parent dari p menjadi merah.
-Jika s berwarna hitam, lakukan rotasi (tunggal atau ganda), ubah pivot rotasi terakhir menjadi hitam dan childnya menjadi merah.
RBT Operations: Deletion
Misalkan simpul yang akan dihapus adalah M, dan childnya adalah C.
-Jika M berwarna merah, maka cukup ganti dengan C
-Jika M berwarna hitam dan C berwarna merah, gantilah dengan C dan warnai kembali C dengan hitam.
Jika M dan C bewarna Hitam;
-Jika M dan C berwarna hitam, ganti M dengan C.
-Nyatakan C dalam posisi barunya menjadi N (dapat disebut double black), parentya menjadi P, siblingnya adalah S, SL menjadi left child S dan SR menjadi right child S.
-Jika S berwarna merah, balikkan warna N dan P, dan putar pada P.
-Jika S, SL dan SR berwarna hitam, maka warnai ulang S sebagai merah.
-Jika S berwarna hitam dan SL atau SR berwarna merah, maka rotate tunggal atau rotate ganda.
Disjoint Sets & Graph
 Set adalah tipe data abstrak yang dapat menyimpan nilai-nilai tertentu, tanpa urutan tertentu, dan tidak ada nilai berulang.
Set adalah tipe data abstrak yang dapat menyimpan nilai-nilai tertentu, tanpa urutan tertentu, dan tidak ada nilai berulang.Disjoint Sets adalah struktur data yang menjaga kesetaraan hubungan.
Pembagian satu set ke banyak kelompok berdasarkan pada relasi ekivalensi disebut partisi
Disjoint Set adalah struktur data yang melacak sekumpulan elemen yang dipartisi menjadi sejumlah subset disjoint (non-overlapping).
Setiap pohon adalah satu set terpisah. Jika dua elemen berada di pohon yang sama, maka mereka berada di set disjoint yang sama. Simpul root (atau simpul paling atas) dari setiap pohon disebut representatif dari himpunan. Selalu ada satu perwakilan unik dari setiap set. Itu merupakan operasi Find, operasi Lalu berikutnya adalah operasi Union. Pertama-tama, Menemukan perwakilan set mereka menggunakan operasi Find, dan akhirnya menempatkan salah satu pohon (mewakili set) di bawah simpul akar dari pohon lain, secara efektif menggabungkan pohon dan set.
Graph

Graph adalah struktur data abstrak yang digunakan untuk mengimplementasikan konsep matematika graph. Pada dasarnya, graph adalah kumpulan simpul (juga disebut simpul) dan tepi yang menghubungkan simpul-simpul ini.
Berdasarkan orientasi arah pada sisi, maka secara umum graf dibedakan atas 2 jenis:
1. Graf tak-berarah (undirected graph)
Graf yang sisinya tidak mempunyai orientasi arah disebut graf tak-berarah.
2. Graf berarah (directed graph)
Graf yang setiap sisinya diberikan orientasi arah disebut sebagai graf berarah.
Minimum Spanning Tree
Algoritma Prim:
1. Buat array dengan nama T.
2. Pilih titik awal.
3. Setiap kali setiap titik menunjuk, ujung yang terhubung akan ditandai sebagai aktif.
4. Bandingkan semua nilai tepi aktif, temukan angka terkecil.
5. Tambahkan node dengan tepi aktif terkecil ke T.
6. Lakukan langkah 3 hingga 5 sementara simpul dalam T lebih sedikit dari total simpul yang ada.
Algoritma Kruskal:
1. Buat array dengan nama T.
2. Urutkan semua tepi menggunakan tumpukan (priority queue)
3. Ambil nilai tepi paling minimum
4. Jika ada loop, lanjutkan ke tepi berikutnya
5. Jika tidak, tambahkan tepi ke T
6. Ulangi langkah 3 hingga 5 hingga semua titik dikunjungi
Algoritma Dijkstra:
1. Pilih simpul sumber (simpul awal)
2. Tentukan N sebagai set kosong
3. Beri label simpul awal dengan 0, dan masukkan ke dalam N
4. Ulangi langkah 5 hingga 7 hingga simpul tujuan berada di N atau tidak ada mode berlabel node di N.
5. Pertimbangkan setiap simpul yang tidak dalam N dan terhubung oleh tepi dari simpul yang baru dimasukkan.
6. a)Jika node yang tidak dalam N tidak memiliki label maka SET label label = label dari node yang baru dimasukkan + panjang tepi
b)Lain jika node yang tidak dalam N sudah diberi label, maka SET label baru = minimum (label titik baru dimasukkan + panjang tepi, label lama)
7. Pilih satu simpul yang bukan di N yang memiliki label terkecil yang ditugaskan padanya dan tambahkan ke N.